用修改的图片引导3D模型编辑,也就是image-guided 3D editing。我们一直在尝试做一个大场景或针对建筑的image-guided 3D editing,没想到物体级别的已经被人做了。
这篇文章用的是多视角图片生成然后引导模型优化,看起来效果很好。目前(2025.08)来说基于图片和视频的解法比3D native的效果好很多。
方法
方法主要分为两个部分: Conditional Multiview Generation和Incremental Reconstruction
Conditional Multiview Generation
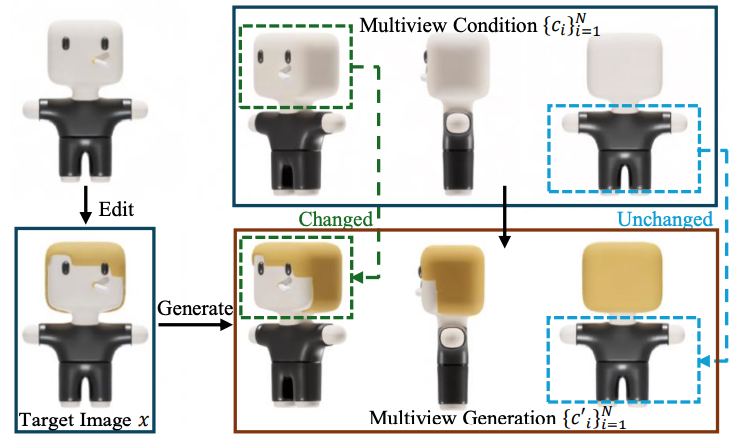
流程主要是给定6个视角下的预渲染图片和normal map,以及其中一个视角下修改后的图片,生成其余5个视角下修改后的图片和normal map,用来引导模型编辑。最主要挑战应该是多视角下图片生成的3D一致性。
- 跨模态多视角Diffusion。多张原始图片,目标图片,Text作为输入,输出多视角生成图片。模型里面加了row-wise multiview attention mechanism between the self-attention and cross-attention layers。
- 多视角限制。多视角ControlNet,UNet结构和参数用的里面的。首先用一个卷积网络提取每个原始图片的feature map,然后和目标图片concatenate在一起作为输入。MVControlNet的输出过一个zero-convolution layer,加到UNet的decoder上去。MVControlNet和backybone一起训练。Era3DGithubEra3DOwnerpengHTYXUpdatedAug 7, 2025


Incremental Reconstruction
这段逻辑写的有点乱……
局部修改只改变一部分的点和面,没必要进行全部重建。他们基于
 对已有模型进行修改。
对已有模型进行修改。
continuous-remeshing
Github
continuous-remeshing
Owner
ProfactorUpdated
Jul 28, 2025第一项对normal map求loss,第二项对shape mask(整体形状的mask)求loss,第三项是正则项让mesh更光滑。
几何建好之后把图片烘焙到纹理上去。
实验
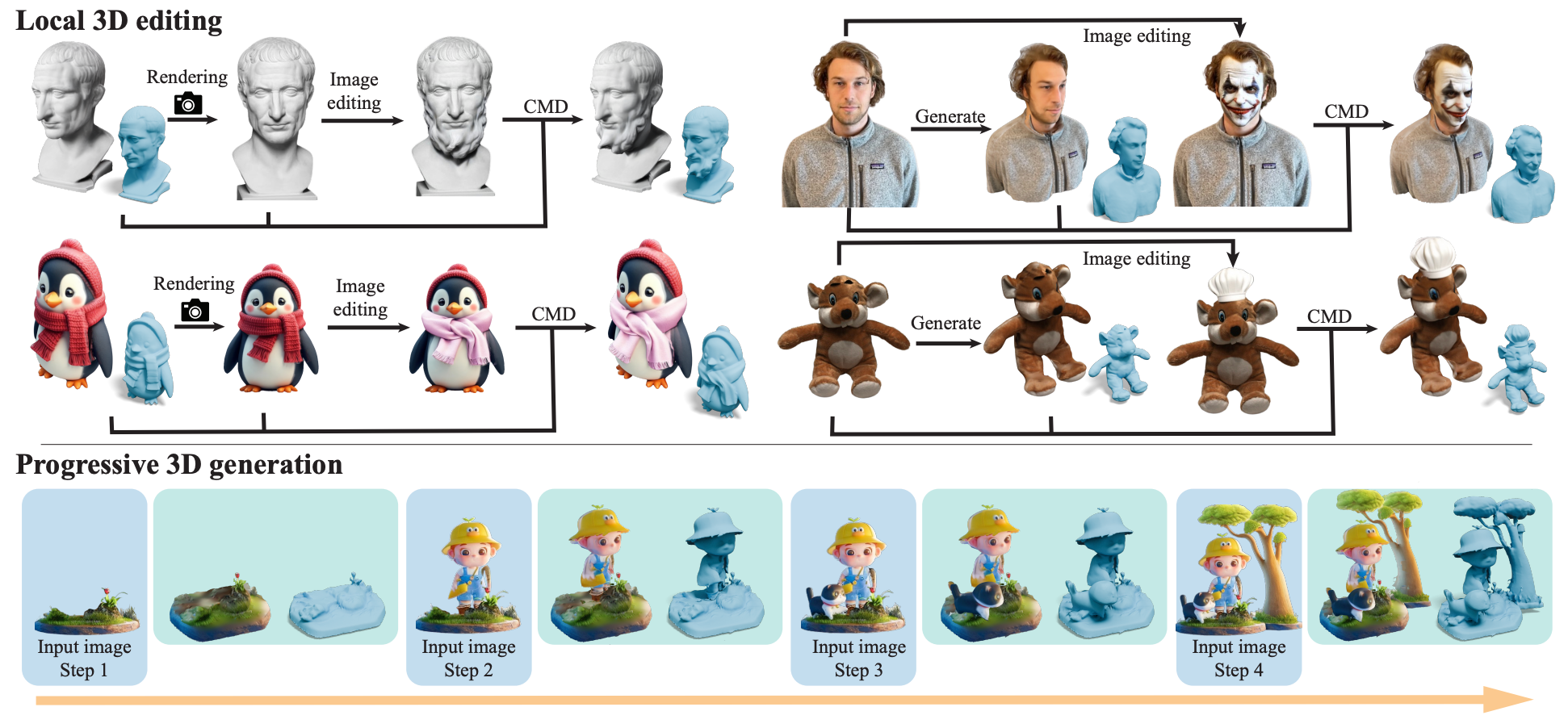
两个任务:局部编辑和渐进生成 (渐进生成的每一步都用了最后的效果图提供3D先验)
数据集:LVIS subset of Objaverse
缺陷
原来模型的拓扑也会随着改变😂
文章写的不好,很多typo和逆天排版错误(Fig. 5和Fig. 12)……